You’ve heard us talking a lot about the Semantic Data Model (I provided a brief summary during the last Webinar, and it’s been covered in some detail on the blog posting back in January). What is it going to mean over the next few months for your Prism 3 catalogue though?
The need to move away from a field based record representation to one made up of links between different entities is very important for improving the user experience in Prism 3. Moving towards a linked data model gives us several benefits:
- your catalogue will become more browsable through the introduction of dedicated pages for authors, subjects, artists, and more
- Prism 3 will also function as an API, allowing other applications or your extensions to tap into and use your data in new ways
- we can weave information from other sources into the item display, augmenting the excellent data already present in your catalogue.
The most important thing to note is that we aren’t “going dark” for an extended period, to emerge with the new data model as a finished item; we’re going to be tackling the task in a series of small, gradual steps. Throughout the next two quarters we’re aiming to provide regular releases when we finish each section, adding value straight away. The first area of data that we’re tackling is format.
Format
The MARC 21 specification offers a rich framework for describing the format of resources that we can mine to get better context for the items in your catalogue; this also underpins other work we want to implement, such as tailoring display of items to the demands of their media; by identifying “what” an item is, we can display context-sensitive enrichment. With CDs this could mean showing track listings fetched from MusicBrainz, and perhaps a short audio preview; with books, a synopsis would be more suitable (from the MARC record, or fetched from an external resource such as LibraryThing); for films, cast and production lists.
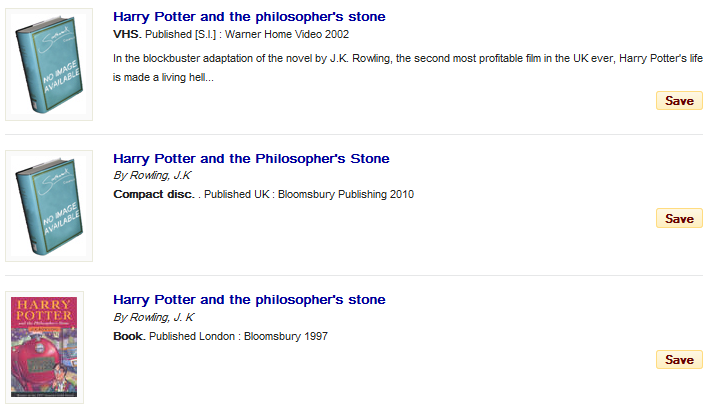
In the work on format, we’re modelling both the form of content, such as dictionary, thesis, film, or poetry, and the carrier format such as Large print, CD or DVD. The model will enable the display of meaningful and specific terms to users in both descriptions and navigation options, such as E-book, DVD, VHS and Blu-ray.
This is dependent on the data, of course. Format information will be extracted from all the relevant standard places in your MARC records and mapped into the data model. Some of the key parts of the MARC record for this include the Type of record and the Bibliographic level (Leader/06 and 07), control fields 007, 008 and 006, as well as data fields such as 300 and some notes.
Books
If an item is classed as a book, the most important field we’ll be looking at is 008. We’ll look at form of item (position 23) for some more specific book types, such as large print or online. The nature of contents and biography data elements (positions 24-27, 34) will provide some of the finer grained formats like biography, dictionary, encyclopaedia and thesis. Literary form (position 33) will allow broader categorisation of material into groups such as fiction, non-fiction, short stories and poetry.
Field 007 also becomes important when dealing with items for readers with visual impairments, such as Braille or large print, so we’ll be looking there for these specific formats too.
With all formats we’ll be looking out for the new “online” form of item (position 23) to help us with identifying online resources and allowing for easy faceting of searches for online-only material.
Serials
For serials, we’ll once again look at the 008. The type of continuing resource (position 21) will help us identify items as newspaper, periodical or database resources. The form of original item (position 22) and form of item (position 23) will be used to flag information like if the item is microfilm, newspaper, large print or Braille. We’ll also be using information available in the 008 position 25-27 to identify formats such as comics/graphic novels.
Visual Material
Visual material is more complex: we’re dealing with many carriers (with a fast pace of change), and the various types of content that can be delivered on them.
The 007 field will be our primary reference: videorecording format (position 04) provides the carrier (DVD, Blu-ray etc.), which will be supported by checks elsewhere such as 538 $a for specific values. By looking at this data element we can separate DVDs, Blu-rays and VHS videos in the faceted search, which is important if a user doesn’t have a particular player and wishes to filter out certain formats.
Audio Recordings
MARC 21 has some very fine-grained types for sound recordings and music, however, identifying the carrier can be a little tricky because the material designation in 007 contains broad categories. CD’s for example aren’t listed so we need to look at 007 position 03 to see a speed of 1.4m/s and position 06 for a diameter of 12cm; we’ll also look at 500 $a and 300 $a. For musical recordings, we’ll be looking in 008 to get the different forms of composition (position 18-19). Position 30-31 will give the work types for literary recordings such as Drama, History, Comedy and Lectures.
Notated Music
Following on from music classification in audio recordings, items that are notated music will have specific data added to our model as well. Format of music (008 position 20) is the primary data element we’ll look at, followed by music parts (position 21) to describe what is included in the score. Target audience and transposition/arrangement (positions 22 and 33) will also be useful when looked at together, for example deriving that a score is a simplified arrangement for younger musicians.
Everything Else
We’ve discussed some formats in detail, but of course there are others, such as maps and computer files. We’ll apply a similar methodology to extracting as much other format information as possible from your records.
We’d love to hear if you have any comments or suggestions on our general approach; if you’d like to give us feedback you can either do it via email to Phil.John@talis.com or by posting a comment here on the blog.

Recent Comments